Strange Evals - Benching Benchmarks
About This Event
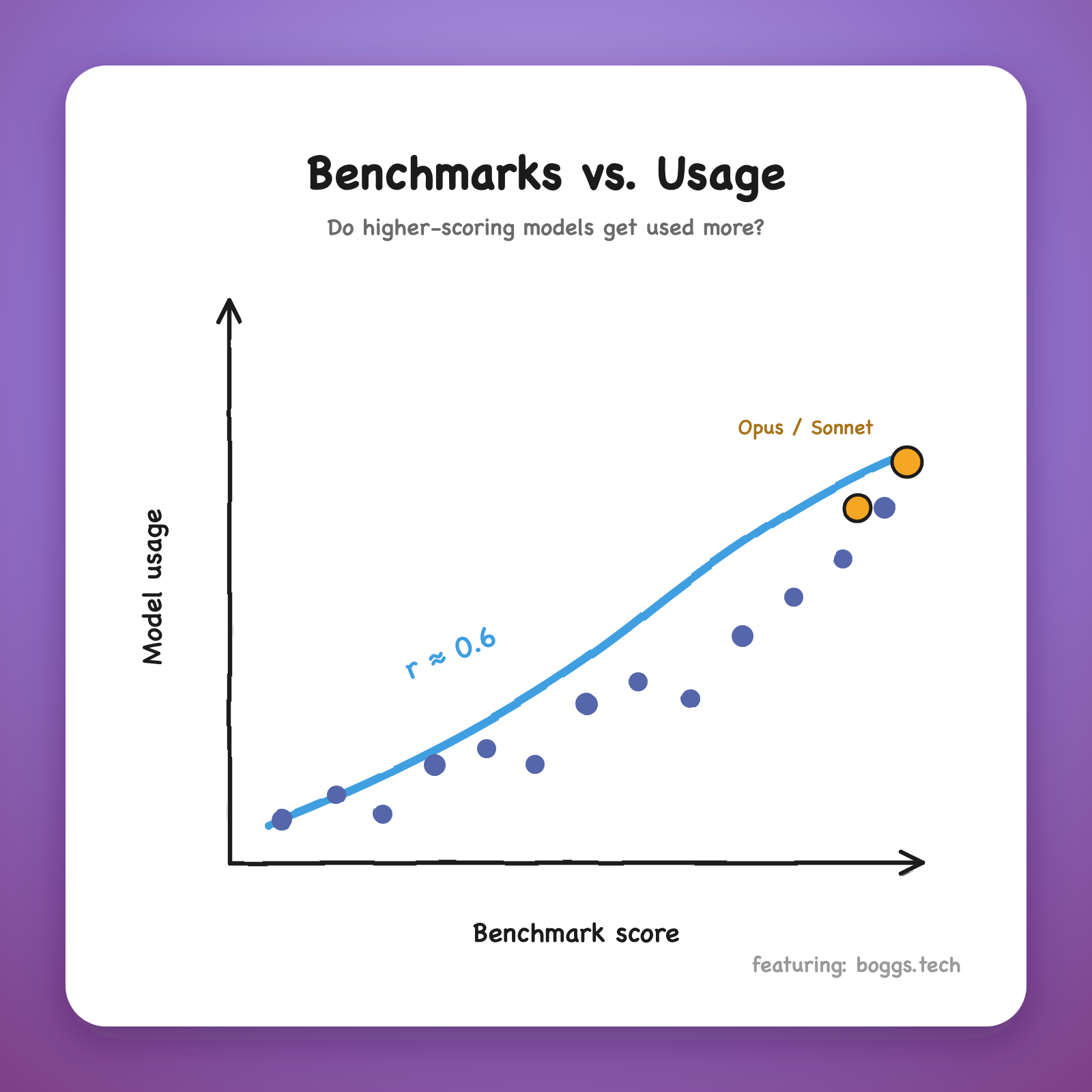
A paper reading club but we deep dive into benchmarks ---- Each session we dive deep on a related battery of widely cited benchmarks so we can develop an intuition about what we're up against. This includes reading papers, but also eyeballing raw benchmark samples (a surprising number of them don't make any sense). This week it's a bit meta: instead of focusing on one benchmark, we'll discuss whether benchmark scores predict real-world model usage. Presenter: Jake Boggs himself --- Pre-reading: https://boggs.tech/posts/can-we-predict-model-usage-from-benchmarks/ --- Special thanks to HUD for hosting us: https://www.hud.ai Attendance will be limited to keep discussion focused.
See the rest of the description and register on Luma.
Share Event
Date & Time
Thursday, June 18, 2026
6:30 PM - 8:00 PM
Location
San Francisco, CA